
Large Language Models have a limited “context window” (short-term memory) for any given prompt. By default, they forget everything outside this window once they complete a response.
To put things in perspective, the context window of OpenAI GPT-4 (Standard) is 8,192 which means Approx. 32,000 Characters or Approx. 6,000 Words or Comparable to 📕 2-3 Chapters of a Standard Novel. This isn’t a sufficient context to solve many real world challenges.
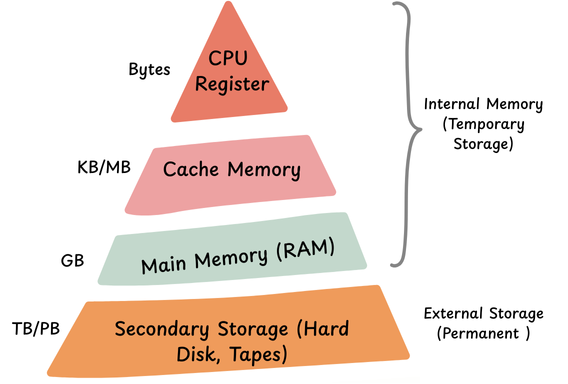
If we look in history, we will find the computers we use today also had exactly similar problem wherein their CPU memory was too little to perform meaningful tasks. It gave birth to many further innovations

Back to LLM – To overcome limited LLM context challenge, developers use memory expansion strategies that let LLMs retain and retrieve information over longer sessions or large documents. This explainer covers how retrieval-augmented generation (RAG), agentic memorysystems like MemGPT, and long-context extensions work to expand an LLM’s effective memory.
1. Retrieval-Augmented Generation (RAG) – External Knowledge Memory
Basic idea: Provide LLM access to an external knowledge base (often via a vector databaseof embeddings). Rather than relying only on what’s in the LLMs trained weights, a pre-step retrieves relevant facts on the fly and adds them to the prompt to LLM.
How it works: When a query comes in, the system generates an embedding (numeric vector) of the query and finds similar vectors (e.g. passages, documents) in an external store. The retrieved text snippets are then prepended or appended to the LLM’s prompt as context. The LLM reads this augmented prompt and incorporates the facts into its generated answer. This process can be summarized as:
- Embed Query: Convert the user’s query or conversation context into a vector.
- Retrieve Documents: Search the vector store for relevant information (knowledge or past interactions).
- Augment Prompt: Insert the retrieved text into the LLM’s prompt (often with citations or markers).
- Generate Response: The LLM produces an answer grounded in both its own knowledge and the provided reference text.

Applicability:
- RAG approach is model-agnostic. It works with open-source models and closed APIs alike, since it just feeds additional text into the prompt.
- Works well when the knowledge base is much larger than the LLM’s context window.
- Ideal for Q&A systems, knowledge retrieval tools, chatbots requiring factual accuracy, etc.
Analogy with CPU:
Like a computer’s disk cache—which receive data from external storage for specific tasks. This way, the LLM can be provided with a knowledge base much larger than its normal memory.
Latest Trends:
For more intelligent retrieval, many enterprises are building Hybrid retrieval approach integrating RAG with Agentic memory architectures (like MemGPT).
Additionally, There are more advanced RAG implementation. They all predominantly focus on improving the accuracy of conext provided to LLM
For further understanding you can also read : pinecode , nvidea, langchain
2. Agentic Memory Systems (Ex -MemGPT)
Basic Idea: Let the LLM itself act as a manager of memory, deciding what to store, where to store it, and when to retrieve it. MemGPT (Memory GPT) is a recent example: it treats the LLM as if it were an operating system process with a limited RAM, and equips it with functions to swap data between “RAM” (context window) and various tiers of external storage. In MemGPT, the LLM has built-in instructions and special tools to save information to a long-term store [outside LLM] or recall it later. It essentially manages its own context, akin to virtual memory in an OS.
How it Works (MemGPT):
- LLM is provided with guidance to define multiple memory tier
— Context Memory: Limited-size working memory (like RAM).
— Recall Storage: Fast external memory (recent interactions, like disk cache).
— Archival Storage: Long-term memory (older or less-used data, like a database).
- The LLM is also given the role of a controller: it can call functions such as STORE or RECALL to move data between these tiers.

Image source: arxiv
Applicability:
- More suitable for open-source models or systems where external orchestration is possible.
- Useful for long-running agents, personalized assistants, or autonomous systems.
- Acts like a database + memory manager where the LLM decides what to remember or forget.
Analogy:
Like an OS memory manager swapping data between RAM and disk.
Latest Trends:
Latest systems focus on building multi-tier memory architectures (RAM, cache, long-term storage) to enhance persistence and contextual understanding over time.
Good reads for further understanding: The reseach paper – arxiv and the example system prompt – huggingface
3. Extended Context – Stretching the Window
Increasing the context window (e.g., GPT-4.5’s 128K tokens, Llama 4’s 10M tokens) allows LLMs to process much longer texts at once. This approach is straightforward but resource-intensive.
Applicability:
- Best suited for commercial LLMs with large context capabilities.
- Useful for analyzing long documents or maintaining detailed conversations.
Analogy: Like adding more RAM to increase the working memory capacity.
Myth buster: Often mistaken, the Extended context doesn’t eliminate the need of MemGPT or RAG like approaches.
RAG is still crucial for scalable knowledge access. Loading vast databases or external knowledge efficiently via retrieval is more practical and cost-effective than loading everything into a context window.
Similar, Agentic Memory solution are essential for persistent, structured memory over long sessions, adapting over time, and managing knowledge actively (e.g., personal assistants, autonomous agents). Large context alone lacks dynamic memory management.
Conclusion and Latest Trends
Combining multiple strategies can give rise to powerful LLM systems that maintain both knowledge and context over time. For example, an advanced chatbot might use RAG to pull in fresh information, a long-context model to maintain a detailed conversation, and an agentic memory module to store important user details for future sessions. The most recent developments (2024–2025) focus on making LLMs more autonomous in managing memory. Techniques like MemGPT and other agentic memory frameworks are at the frontier, allowing LLMs to function more like an operating system with RAM and disk, rather than a stateless predictor.
On the commercial side, I see APIs offering larger context windows and plugins for retrieval (e.g. tools that integrate vector stores), hinting that long-term memory will soon be a standard feature.
Credit – Thanks to my MIT professors Abel Sanchez & John R. Williamsfor thoughtful discussions on these topics.
𝙉𝙤𝙩𝙚 – The views expressed are personal.
#AI #AppliedAI #EnterpriseAI #FinTech #DataSecurity #Innovation #CostEfficiency #GenAI
About the Autor
Prabhat Kumar is a visionary voice in AI architecture, passionate about aligning GenAI with societal good and sustainable progress.
Through his writing, he shares future-forward insights that connect technology with purpose.
Originaly published on LinkedIn on Apr 8 2025